
Le machine learning est de plus en plus un processus continu
L'adage selon lequel 'on n'a jamais fini d'apprendre' ne s'applique plus seulement aux humains
Grâce au 'machine learning' (ou apprentissage automatique), l'adage selon lequel 'on n'a jamais fini d'apprendre' s'applique aux humains mais aussi aux machines. En formant des modèles sur base de données, les machines apprennent à faire des prédictions, à reconnaître des schémas et/ou à prendre des décisions. Des développements tels que le méta-apprentissage, l'apprentissage par transfert et l'apprentissage exploratoire portent le machine learning (ML) à des niveaux toujours plus élevés, tandis que l'Explainable AI et l'Automated Machine Learning, entre autres, veillent à ce que tout cela ne dépasse pas le cerveau humain.

Principe
L'idée derrière le machine learning (ci-après ML) - un sous-domaine de l'intelligence artificielle (IA) - est d'entraîner des modèles sur base de données afin qu'ils soient capables, au fil du temps, de faire des prédictions, de reconnaître des modèles et/ou de prendre des décisions. Cela implique l'utilisation d'une combinaison de logiciels et de matériel qui peuvent être utilisés pour analyser des 'big data'. Le principe est le suivant: une bonne analyse des bonnes données permet de mieux comprendre le fonctionnement et le comportement des machines et des installations. Mais qu'est-ce qu'une bonne donnée et qu'est-ce qu'une bonne analyse?
De bonnes données
Toute forme de 'data analytics' dépend de la qualité des données. Celles-ci sont souvent abondantes, mais leur qualité laisse souvent à désirer. Ainsi, il manque souvent certaines caractéristiques pertinentes et un mélange de données de test et de données opérationnelles, par exemple, ne constitue pas un point de départ idéal. Étant donné la puissance des ordinateurs nécessaires pour analyser ces données, il est important d'investir dans la qualité des données ('garbage in, garbage out').
Une bonne analyse nécessite la capacité de placer les données dans le bon contexte et de les interpréter correctement
Bonne analyse
On peut parler d'une bonne analyse lorsqu'on a une évaluation aussi approfondie que systématique d'un ensemble de données créé. Les concepts clés ici sont la structure et le raisonnement logique. En outre, une bonne analyse doit être exempte de préjugés et/ou d'interprétations subjectives. Il est important de se concentrer sur les aspects pertinents pour l'objectif d'analyse formulé, tout en ayant - et en gardant - un œil sur les causes sous-jacentes et/ou les modèles. Une bonne analyse nécessite la capacité de placer les données dans le bon contexte et de les interpréter correctement.

Apprentissage continu
L'apprentissage est devenu un processus continu pour les humains. Et il en va de même pour les machines, grâce au ML. Par exemple, les continual learning-algorithms permettent aux modèles de s'adapter en permanence à des conditions changeantes et à de nouvelles données, sans compromettre ce qui a été appris précédemment, ce qui est essentiel pour les applications dans lesquelles les données et les conditions sont susceptibles de changer.
Le méta-apprentissage et l'apprentissage par transfert ont permis à un modèle d'être non seulement performant dans les tâches spécifiques pour lesquelles il a été formé, mais aussi de fonctionner efficacement dans des situations jusque-là inconnues. Cela réduit le besoin de grandes quantités de données étiquetées (voir le point 'Semi-supervised en supervised learning') tout en améliorant l'efficacité de la formation.
Les progrès réalisés dans le domaine de l'apprentissage dit exploratoire sont également remarquables. Celui-ci permet aux modèles d'explorer et d'apprendre de nouvelles tâches et/ou de nouveaux environnements sans intervention humaine, ce qui ouvre la voie à un plus grand degré d'automatisation dans le processus de ML.
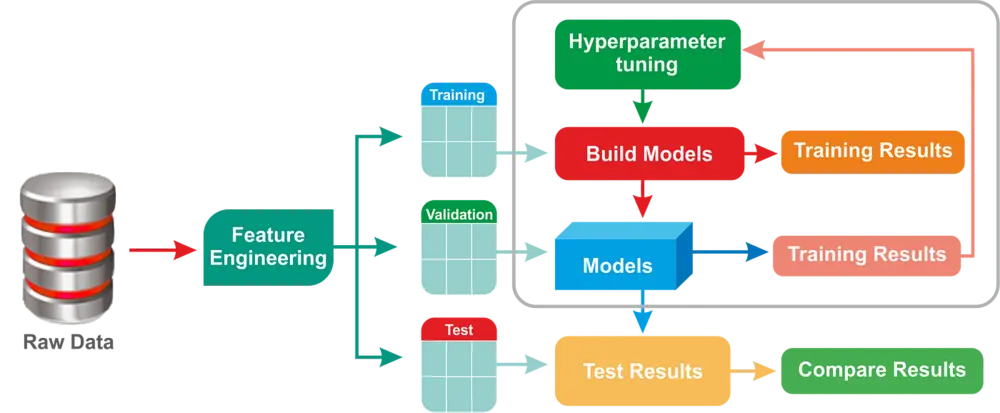
Formes de ML
Une conséquence logique des développements décrits ci-dessus est une croissance permanente du nombre de formes de ML.
Deep learning
Ici, les modèles apprennent à reconnaître, à regrouper et à classer des schémas et des relations à l'aide de réseaux neuronaux (voir l'encadré). Ainsi, les machines sont en mesure de traiter et de comprendre des masses de données, de reconnaître des modèles et de prendre des décisions sur cette base. Cela permet l'apprentissage à plusieurs niveaux d'abstraction, ce qui permet d'étendre la gamme des tâches à des éléments tels que la reconnaissance d'images, la reconnaissance vocale et le traitement du langage naturel.
Federated learning
Ici, le processus d'apprentissage est décentralisé: l'entraînement a lieu sur plusieurs appareils ou serveurs qui conservent les données localement. Le modèle est envoyé directement aux appareils - les informations sensibles en matière de confidentialité restent sur place - et les paramètres actualisés du modèle sont collectés périodiquement et combinés sur un serveur central. Cela permet de former des modèles avec des données réparties sur différents sites.
Reinforcement learning
Il s'agit pour un agent, en l'occurrence une machine, d'apprendre à tirer le meilleur parti de son interaction avec l'environnement. Au cours de ce processus d'apprentissage, il y a un retour d'information: les actions favorables sont récompensées, les actions défavorables sont sanctionnées; il n'y a pas d'instructions explicites. L'objectif final est de parvenir à une stratégie qui conduise au résultat souhaité par le biais d'essais-erreurs.
Semi-supervised et supervised learning
Le semi-supervised learning implique une approche hybride utilisant à la fois des données étiquetées et des données non étiquetées. Dans le cas des données étiquetées, chaque instance de données est associée à une étiquette/catégorie qui représente le résultat souhaité; elles servent de 'réponses correctes' ou de 'classifications correctes' pour les instances de données. La variante non étiquetée en est dépourvue. Le supervised learning utilise uniquement un ensemble de données étiquetées.

Tiny Machine Learning (TinyML)
Cette forme d'apprentissage convient aux appareils dont la puissance de calcul, le stockage d'énergie et/ou la capacité de mémoire sont limités. Elle exige des gains d'efficacité en ce qui concerne la quantification et la compression des modèles (voir encadré) et l'utilisation de matériel spécialisé. En transférant l'intelligence aux dispositifs périphériques, ceux-ci sont de plus en plus capables de fonctionner de manière autonome et efficace dans des applications en temps réel, par exemple les capteurs intelligents et les dispositifs IoT.
Transfer learning
L'apprentissage par transfert se produit lorsqu'un modèle formé pour une tâche spécifique est utilisé pour une tâche connexe. Le modèle peut alors 's'appuyer' sur les connaissances acquises à un stade antérieur, de sorte qu'il n'est pas nécessaire de reprendre le processus depuis le début. Le processus d'apprentissage est donc plus rapide, moins coûteux et permet d'obtenir de meilleures performances.
Unsupervised learning
Ici, on utilise des données non étiquetées (voir plus haut). L'objectif est de découvrir des modèles ou des structures cachés dans un ensemble de données sans utiliser d'étiquettes connues au préalable. Cette approche permet souvent de mieux comprendre la nature et la structure des données, ce qui peut conduire, par exemple, à l'identification de clusters et à la feature extraction.

(illustration: Medium)
La boîte de Pandore?
La progression du ML est un fait, et pour certains, cela évoque la boîte de Pandore, ou la perte de contrôle. L'Explainable AI , ou XAI, prouve que ce phénomène a déjà été anticipé. Il s'agit d'un système d'intelligence artificielle capable d'expliquer de manière transparente et compréhensible pour un être humain les conclusions qu'il tire et/ou les prédictions qu'il fait. Cela est possible, entre autres, en utilisant des algorithmes interprétables et en rendant la prise de décision accessible.
Étant donné l'avènement d'algorithmes, de techniques et d'approches toujours plus récents, le ML ne va pas disparaître de sitôt
Pour éviter que l'apprentissage automatique ne devienne l'apanage de quelques happy few - lire: d'experts - il existe l'Automated Machine Learning (Auto-ML), une forme d'apprentissage automatique qui vise à faciliter l'utilisation de l'apprentissage automatique pour les non-experts et qui ne nécessite donc pas une connaissance approfondie des algorithmes et des techniques sous-jacents. Cela simplifie non seulement le réglage des hyperparamètres (voir encadré), mais la ML prend également en charge la sélection et l'entraînement des modèles et effectue une série d'optimisations automatiques, y compris la préparation des données, la sélection et la validation des modèles.

(illustration: Altexsoft)
Une valeur sûre
Etant donné l'avènement d'algorithmes, de techniques et d'approches toujours plus récents, le ML est sans aucun doute une 'valeur sûre'. On s'attend à une nouvelle évolution vers l'edge computing et le ML on-device (voir encadré). Cela conduira à une inférence plus rapide - dériver de nouvelles connaissances à partir du savoir-faire existant - à une meilleure protection de la vie privée et à une réduction de la dépendance vis-à-vis des services cloud.
L'apprentissage multimodal est une nouvelle branche. Cette forme de ML, qui en est encore à sa phase exploratoire, consiste à combiner des informations provenant, par exemple, de textes, d'images, de discours et/ou de vidéos qui permettent au modèle de faire des prédictions (plus) précises ou d'effectuer des tâches (plus) complexes.
De telles innovations, et d'autres encore, permettront sans aucun doute au ML de passer à la vitesse supérieure. Malheureusement, les modèles de ML doivent de plus en plus résister à toutes sortes d'attaques externes, telles que les attaques adverses (voir encadré) et/ou les changements dans la distribution des données. La sécurité d'abord! En effet, la cybercriminalité guette aussi le ML.
Concepts importants
Attaques adverses, modifications délibérées des données d'entrée afin de tromper le modèle ou de générer des prédictions erronées.
Edge computing, technologie informatique distribuée qui facilite le traitement local des données de sorte que seules les informations pertinentes doivent être envoyées dans le cloud. Cela réduit les coûts de bande passante et de transfert de données et offre des avantages en termes de cybersécurité.
Hyperparameter tuning, étape du processus au cours de laquelle les hyperparamètres d'un modèle de ML - par exemple le taux d'apprentissage et la taille du lot - sont réglés afin d'optimiser les performances. Cette opération doit être effectuée avant le processus d'apprentissage.
Quantisation, réduction de la précision des calculs numériques - par exemple, en réduisant le nombre de bits représentant les poids et les activations dans les réseaux neuronaux - afin d'améliorer l'efficacité des appareils dotés d'une puissance de calcul limitée.
Compression de modèle, utilisée pour réduire la taille des modèles ML sans compromettre leur performance prédictive. Un processus d'expérimentation et de réglage fin devrait ainsi permettre de trouver un juste équilibre entre la taille et la performance.
Réseaux neuronaux, modèles d'IA avec des nœuds interconnectés(nodes) dont la structure est basée sur les cellules nerveuses du cerveau humain. Grâce à l'entraînement, ces nodes apprennent à reconnaître des modèles et des relations, à les regrouper et à les classer.
On-device ML, c'est-à-dire lorsque l'entraînement des modèles de ML a lieu directement sur l'appareil plutôt que sur des serveurs distants ou dans le cloud. Cette méthode est plus rapide et nettement plus sûre.
En collaboration avec Lenze
